GitHub CopilotでSlackを操作するMCP Slack Serverを呼び出す (VS Code)
今回は、GitHub Copilotで、Slackを操作するMCP(Model Context Protocol) Serverを動かす例を紹介します。
GitHub Copilotから、Slack MCP Serverを使うことで、簡単にSlack APIを活用したメッセージ取得や投稿、リアクションを実現できるようになります。
Slack MCP Serverの持つ機能
Slack APIのMCPサーバーは、Slackワークスペースとやり取りするための次のツールを提供します。
次の8つのツールがあります。
- チャンネル一覧取得 (slack_list_channels): ワークスペース内の公開チャンネルのリストを取得します。
- メッセージ投稿 (slack_post_message): 指定チャンネルにメッセージを投稿します。
- スレッド返信 (slack_reply_to_thread): 特定のスレッドに返信します。
- リアクション追加 (slack_add_reaction): メッセージに絵文字リアクションを追加します。
- チャンネル履歴取得 (slack_get_channel_history): チャンネルの最近のメッセージを取得します。
- スレッド返信取得 (slack_get_thread_replies): スレッド内の返信をすべて取得します。
- ユーザー一覧取得 (slack_get_users): ワークスペースのユーザーリストを取得します。
- ユーザープロフィール取得 (slack_get_user_profile): 特定ユーザーの詳細プロフィールを取得します。
Slack環境の準備
今回、MCP Serverと連携するにあたって、新しいSlack環境を作成します。無料で作成できます。
URLからサインアップします。
ワークスペース名などを入力するだけです。
Slack Appの作成
Slack MCPサーバーはSlack App(Slack アプリ)からSlackのAPIを呼び出します。
そのためSlack Appを作成します。
まず、[Create an App]ボタンをクリックします。
Appをインストールするワークスペースを選択します。

次に、From manifestという、マニフェスト方式の設定を選択します。

このSlackのアプリマニフェスト(App Manifest)は、Slackアプリケーションの設定を定義するJsonファイルです。

アプリの名前、説明、権限スコープ、機能などをJSONで管理できるので、ここでは、以下のアプリ名とスコープを変更したマニフェストを貼り付けます。
{ "display_information": { "name": "VS Code MCP App" }, "features": { "bot_user": { "display_name": "VS Code MCP App", "always_online": false } }, "oauth_config": { "scopes": { "bot": [ "channels:history", "channels:read", "chat:write", "reactions:write", "users:read" ] } }, "settings": { "org_deploy_enabled": false, "socket_mode_enabled": false, "token_rotation_enabled": false } }
アプリ名や表示名は自由に変更して、[Create]を選択します。
作成されたSlack Appの確認
Slack Appが作成されると、Web画面で設定を確認することができます。
権限の確認
Appを作る時のマニフェストでは、すでに必要なスコープ(操作権限)が追加されています。
[OAuth & Permissions]にて確認できます。

Slack MCP Serverに必要な権限は次の5つです。
- channels:history - 公開チャンネル内のメッセージやその他のコンテンツを閲覧する
- channels:read - チャンネルの基本情報を閲覧する
- chat:write - アプリとしてメッセージを送信する
- reactions:write - メッセージに絵文字リアクションを追加する
- users:read - ユーザーとその基本情報を閲覧する
Slack MCPでは、これらの権限を利用して操作ができます。
Slack ワークスペースへSlack Appをインストール
それでは、作成したSlack Appを利用できるようにワークスペースへインストールします。
Install Appサイドバーから、[Install to ワークスペース名]をクリックします。
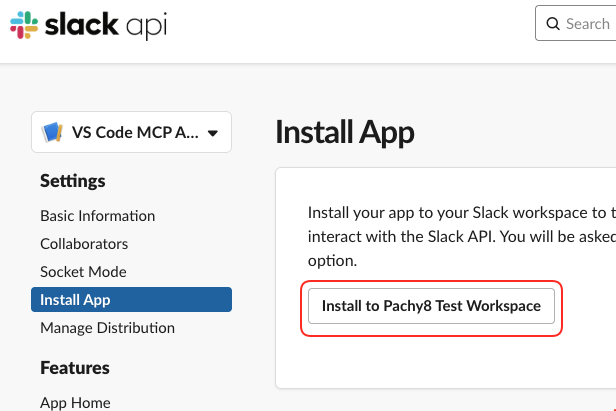
ワークスペースへMCPアプリをインストールして良いかの確認画面がでます。
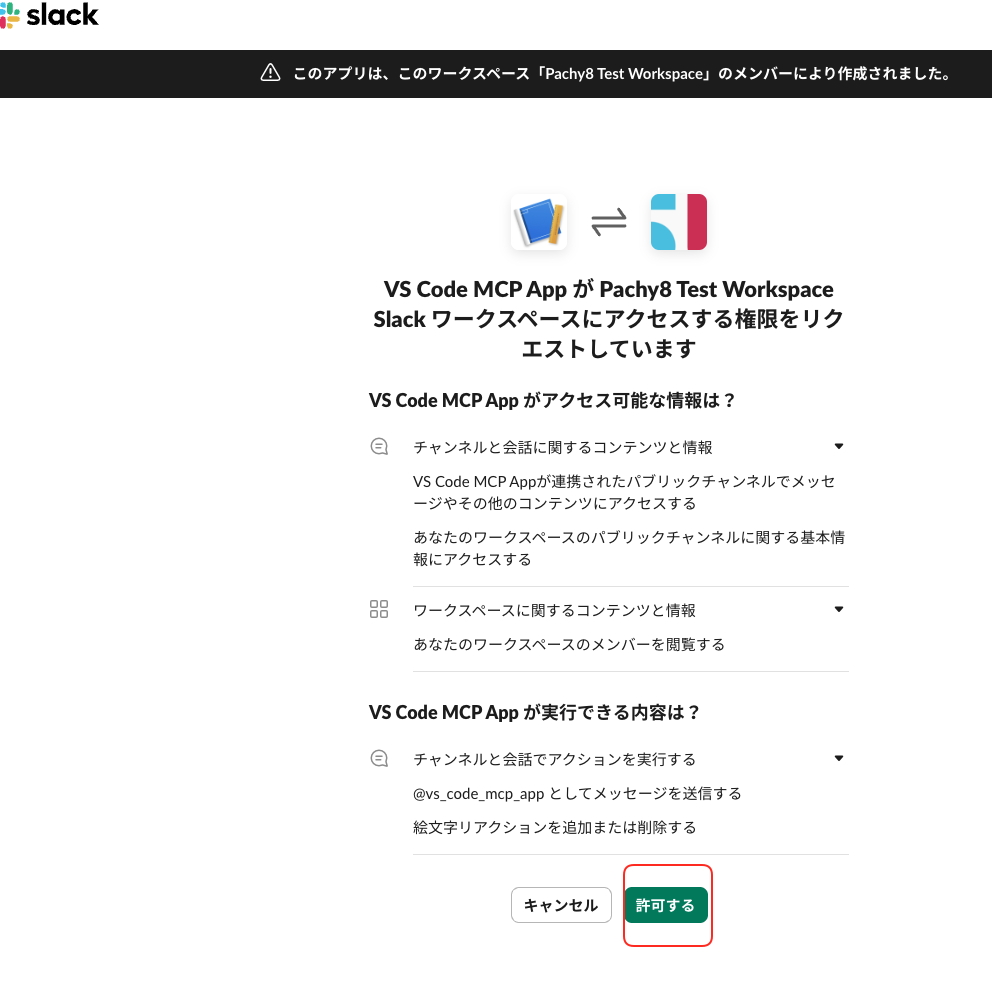
[許可する]をクリックします。
これで「Bot User OAuth Token」が生成されます。このトークンを使ってSlack Appの認証を行います。
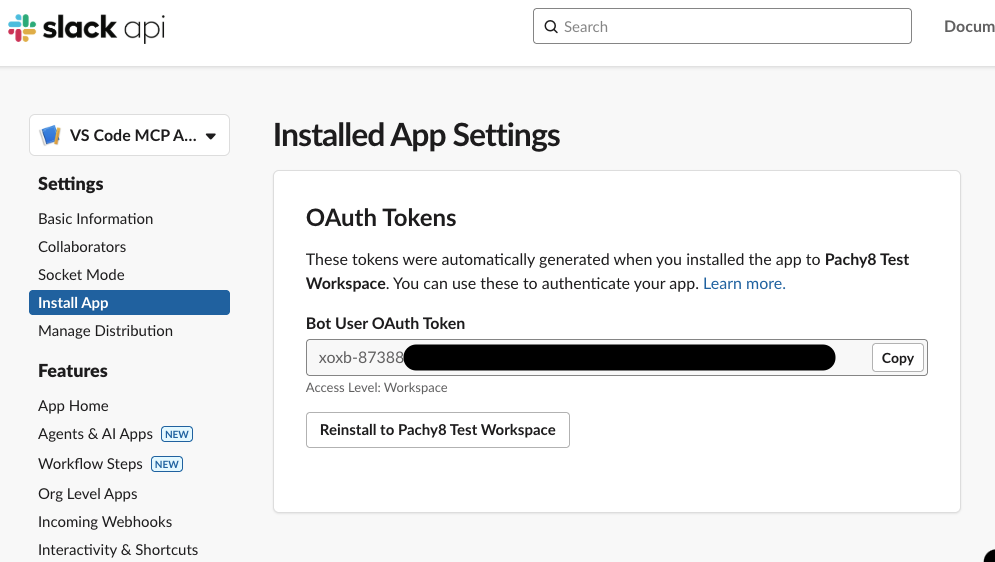
この値はコピーしておきます。後ほどのMCP設定のつまりSLACK_BOT_TOKENとして使用します。
Slack MCPの環境変数
なお、Slack MCP Serverを設定するときには、次の2つのSlackの環境変数(パラメータ)が必要となります。
SLACK_BOT_TOKENSLACK_TEAM_ID
SLACK_BOT_TOKENは上記で確認できましたので、次にSLACK_TEAM_IDを確認します。
Team IDの確認
SLACK_TEAM_IDはワークスペースのURLでslack.comの前の部分となります。ここではpachy8testworkspace となります。

Slackの環境設定ができたので、次は、Slack MCPを設定してきます。
Slack MCPサーバーの設定
それでは、MCP Slack Serverを設定していきます。
MCP Slack Serverは、Node.jsのアプリで提供されています。
2つの起動方法があります。
- サーバーリソースををnpmリポジトリからダウンロードしてきて、
npxで動作させる方法 - dockerでnode環境を作り起動する方法
ここでは、1番の方法で設定を行います。
Dockerで動作させたい場合は、こちらのリポジトリをCloneして、Readmeの説明に従ってください。
MCP Slack Serverをnpxで動作させる
それでは、npxコマンドでローカルPCで動作させていきます。
Nodeバージョンの準備
まず、Node環境を準備します。
npmサイトのpackage.jsonによれば、@types/node": "^22のため、node.jsのバージョンを22としておきます。
# 現在最新のNode22の表示 % npm view node@22 version # ここではnコマンドで、最新をインストール。 # nodebrewなど必要に応じて切り替えてください % n 22.14.0 installing : node-v22.14.0 mkdir : /Users/xxx/.n/n/versions/node/22.14.0 fetch : https://nodejs.org/dist/v22.14.0/node-v22.14.0-darwin-arm64.tar.xz copying : node/22.14.0 installed : v22.14.0 (with npm 10.9.2) # バージョンを確認 % node --version v22.14.0
VS CodeにMCPを追加するために、以下を設定します。
% code --add-mcp '{"name":"slack","command":"npx","args":["-y","@modelcontextprotocol/server-slack"],"env":{"SLACK_BOT_TOKEN":"{トークン}","SLACK_TEAM_ID":"{チームID}"}}'
このコマンドを追加すると、setting.jsonが更新されます。
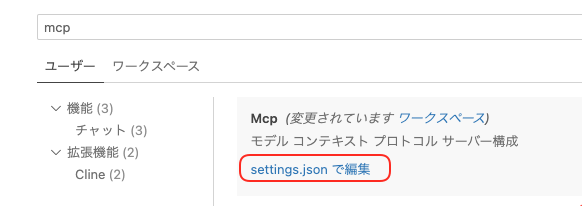
次のように設定されています。
code --add-mcpコマンドを叩く代わりに、このJson設定を手動で入れても問題ありません。
{ ... "mcp": { "inputs": [], "servers": { "slack": { "command": "npx", "args": [ "-y", "@modelcontextprotocol/server-slack" ], "env": { "SLACK_BOT_TOKEN": "{トークン}", "SLACK_TEAM_ID": "{チームID}" } } } }
VSCodeからSlackの操作できるか確認
Slack MCP Serverの設定ができたので、CopilotからSlackに話しかけてみます。
チャンネル情報・一覧の取得(slack_list_channels)
まず、チャンネル情報を取得します。まずは、
test-public1
について
というSlackチャンネル名を、VS CodeのGithub Copilotから、問い合わせてみます。
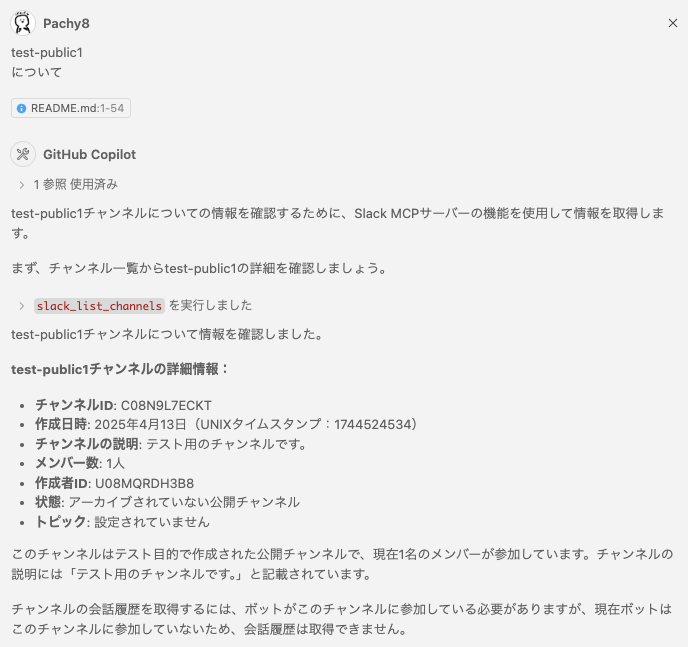
無事、Slackから[ test-public1]というチャンネルがあることと詳細情報を取得できました。
会話履歴の取得(slack_get_channel_history)
次に、そのチャンネルの会話履歴を取得します。
ただ、チャンネルの会話を取得するためには、チャンネルにSlack Appが参加している必要があります。
そのため、Slackの画面からAppを追加します。チャンネルのメンバアイコンをクリックします。
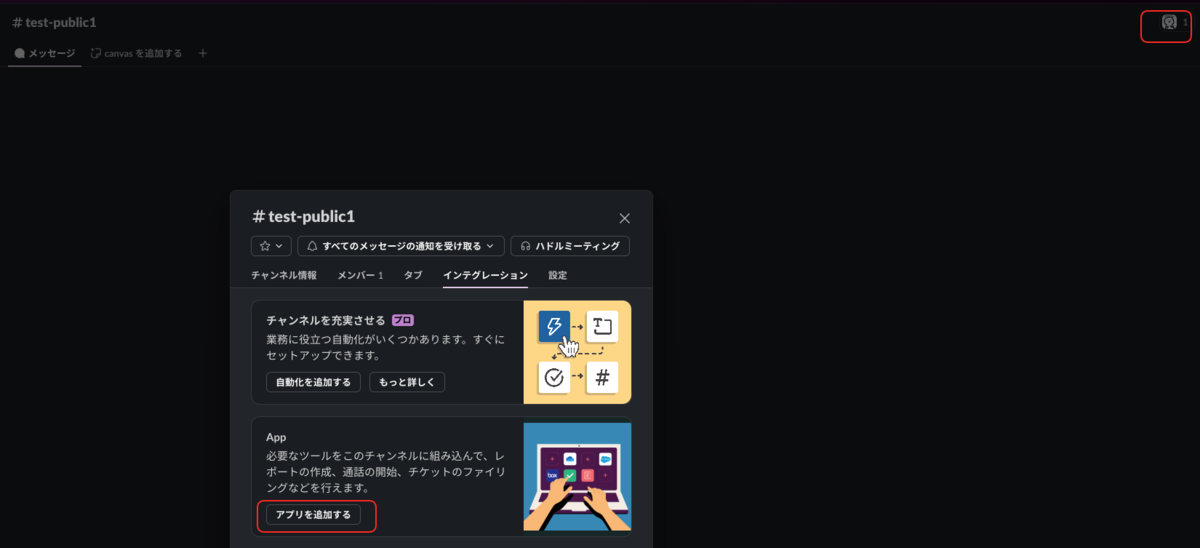
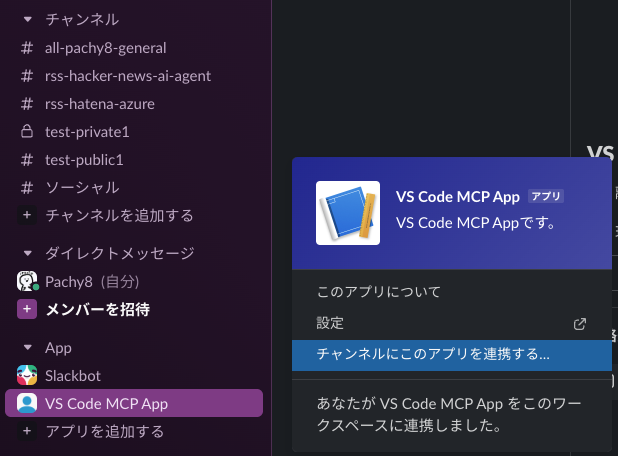
次に、今回のアプリである「VS Code MCP App」をチャンネルに追加します。
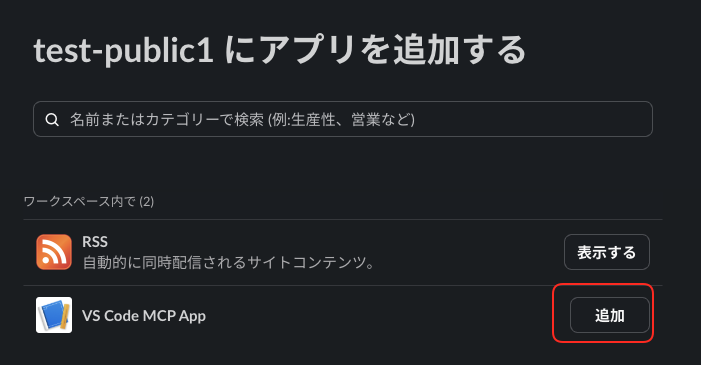
無事追加できたので、チャンネルの会話についてVS Codeから問い合わせてみます。
test-public1 の履歴を取得して
というメッセージを送ります。

こちらも、無事、チャンネル内で会話された内容が取得できました。
メッセージの送信 (slack_post_message)
それでは、会話履歴をみたこのチャンネルにメッセージを送信してみます。
このチャンネルで、"こんにちは。Slack MCPです"と投稿して。
送信したいメッセージを、Copilotに伝えると、そのまま送信してくれました。
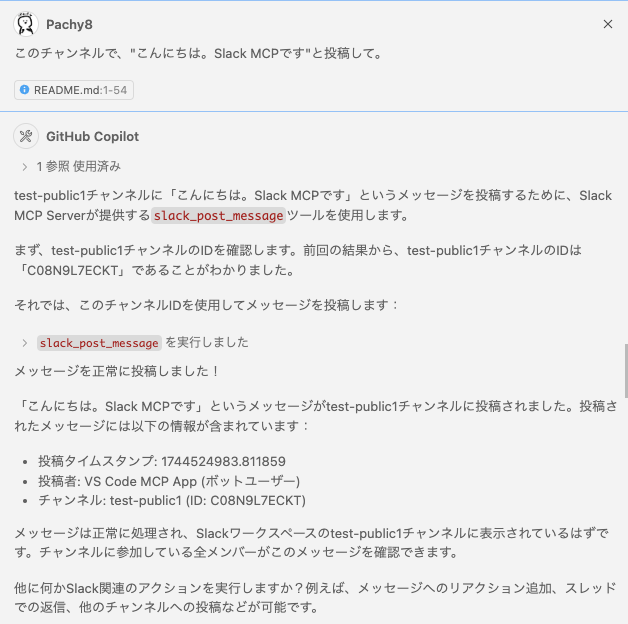
Slack画面でも、問題なく送信されていることが確認できます。

RSS フィードのチャンネルを読み込んで、Playwright MCPでWebページを読み込み
基本的な操作はできたので、他のMCP Serverを組み合わせた操作も行ってみます。
ここでは、次の手順で動作させてみます。
- Slackチャンネルに設定しているRSSフィードを読み込み
- Playwright MCPでブラウザから読み込んで内容を要約
Slack RSS アプリの設定
SlackでRSSフィードを読み込むにはRSS Appを追加するだけです。

RSSのページで、フィードを登録します。

例:https://hnrss.org/newest?q=ai%20agent
アプリをRSSフィードを出力するチャンネルに追加します。
Slackの設定は以上です。
ブラウザを操作するPlaywright MCP Serverの設定
こちらの手順で、Playwright MCPを設定します。
VSCodeからRSSフィードを読み取り
ここでは、VS Codeから以下の依頼を行います。
Slackで、ハッカーニュースの最近のニュースを教えて。
対象チャンネルを見つけて、一番新しいページを見つけてくれました。
ここでは、「AIエージェントでコーディング面接をする」記事が見つかっています。
RSSフィードに接続したSlackチャンネルから、最新のニュースを読み取って見ます。

本来の記事は英語ですが、日本語で、読みやすく整理してくれていることがわかります。
VSCodeからブラウザを起動して情報の読み取り
次に、
この記事をWebで開いて、記事の内容をもっと詳しく教えて。
と依頼します。

これで、先程のRSSフィードの記事を、ブラウザで読み取りまとめることができました。他のMCPサーバーと組み合わせて活用するアイデアを考えても面白そうです。
以上、この記事では、GitHub CopilotからSlackを操作するMCP Serverを紹介しました。この連携により、メッセージの取得や投稿、リアクションなどが簡単にできることがわかりました。
参考にしたサイト
素敵な情報ありがとうございます。
Macで「dotnet --list-sdks」がおかしい(インストーラ版とbrew版のdotnet SDKバージョンの切り替え)
無駄にハマったので、記録しておきます。
.NETコマンドのバージョン 8とバージョン9の混在環境が必要だったのですが、homebrewからインストールしたものと、インストーラからダウンロードしたものが混在した結果、期待するdotnetバージョンが動作しませんでした。
結論としては、パスとバージョン管理がややこしいため、共存は諦め、brew版を全部消しました。
ちなみに、Apple シリコン系のMacです。
発生した問題
dotnet --list-sdksコマンドを実行しても、brew版だけが表示されてしまう。.NET正規インストーラーから導入したバージョンが動作しないという問題です。
% dotnet --list-sdks 9.0.105 [/opt/homebrew/Cellar/dotnet/9.0.4/libexec/sdk]
というように、homebrew版の1つだけが表示されます。
原因は自分が適当にbrew版でインストールしたためだと思います。
brew版でも、SDKの切り替えをおこなうTapはあり感謝はしつつも、やや野良サイト感もあり、私はリスクを取らない解決策を選択しました。
対応内容(brew版をすべて削除)
ここでは、すべての正規サイトのインストーラから導入したバージョンのみを使用します。
(.zshrcなどで、混在させようと少し試しましたが、パスが汚く、余計にわかりにくいと思いました。)
そのため、brew版を全部削除します。
# dotnetを強制的に削除 brew uninstall --force dotnet # Homebrewのキャッシュをクリーンアップ brew cleanup # dotnet関連のシンボリックリンクを確認 ls -la /opt/homebrew/opt/ | grep dotnet # 必要に応じてシンボリックリンクを手動で削除 rm -f /opt/homebrew/opt/dotnet
インストーラー版側が表示されることを確認します。
# dotnetのパスを確認 ~ % which dotnet /usr/local/share/dotnet/dotnet ~ % dotnet --list-sdks 8.0.405 [/usr/local/share/dotnet/sdk] 8.0.408 [/usr/local/share/dotnet/sdk] 9.0.203 [/usr/local/share/dotnet/sdk]
Dotnetのバージョンが選択される仕組み
基本的には、 global.jsonを使用されます。存在しなければ、最新が使用されます。
↓SDK バージョンを選択するプロセス
dotnet は、現在の作業ディレクトリからパスを上方向に逆移動する global.json ファイルを繰り返し検索します。
dotnet は、最初に見つかった global.json で指定された SDK を使用します。
dotnet は、global.json が見つからない場合は、インストールされている最新の SDK を使用します。
この仕組みにより、複数の.NETバージョンをインストールしておいても、開いたプロジェクトごとに適切なバージョンが選択されます。
正規ダウンロードラーからインストールした場合のパス設定
.NET8バージョンのSDK URLです。
.NET9バージョンのSDK URLです。
これらをインストールした場合は、システムパス(コンピューター共有のパス)にdotnetが追加されます。
% cat /etc/paths.d/dotnet
/usr/local/share/dotnet
以下はBrew側の補足です(今回は非推奨)
homebrewを利用した場合の挙動です。今回はbrewをすべて削除しましたが、とりあえず特定のバージョンだけ使えれば良いということであれば、次のようなコマンドが使用できます。
brewでの導入コマンド
# .NET バージョン8をbrewインストール % brew install dotnet@8 Warning: dotnet@8 8.0.15 is already installed and up-to-date. To reinstall 8.0.15, run: brew reinstall dotnet@8 # .NET バージョン9をbrewインストール % brew install dotnet@9 ... ...
以下はbrew版を使うと利用されるパスです。
.zprofileの以下のコマンドが実行されます。
eval "$(/opt/homebrew/bin/brew shellenv)"
その結果、以下のようなパスが追加されます。
export PATH= ... /usr/local/share/dotnet:\ ~/.dotnet/tools:\ /opt/homebrew/opt/dotnet//bin" ...
私の場合はこれらのパス設定と.zshrcが混ざり、dotnetコマンドのパスが複数設定されて、挙動確認が複雑になってしまいました。
結局、.zshrcからはすべて削除して、インストーラ版のシステムパスだけで動かしています。
参考
ツールによって、いくつものパスがあることが理解できました。ありがとうございます。
Daprを操作する「Dapr CLI」の概要
Daprを操作していると、dapr init や dapr runといったdaprコマンドを使用します。
今回はこのdaprコマンドについて確認します。
dapr CLIの導入
これまではDevコンテナ(Dockerイメージ)を利用していたため、daprコマンドについて手動導入する必要はありませんでした。
もし、手動で導入したい場合は、以下のページのコマンドでインストールを行います。
Dapr CLIのコマンド一覧
ヘルプのパラメータを付与すると、daprのコマンド一覧を見ることができます。
$ dapr -h 分散アプリケーションランタイム 使用法: dapr [flags] dapr [command] 利用可能なコマンド:
(以下、機械翻訳しています)
| コマンド | 説明 | Kubernetes | セルフホスト |
|---|---|---|---|
annotate |
Kubernetes構成にDaprアノテーションを追加 | ◯ | - |
build-info |
Dapr CLIとランタイムのビルド情報を表示 | ◯ | ◯ |
completion |
シェル補完スクリプトを生成 | ◯ | ◯ |
components |
すべてのDaprコンポーネントを一覧表示 | ◯ | - |
configurations |
すべてのDapr構成を一覧表示 | ◯ | - |
dashboard |
Daprダッシュボードを起動 | ◯ | ◯ |
help |
コマンドに関するヘルプを表示 | ◯ | ◯ |
init |
サポートされているホスティングプラットフォームにDaprをインストール | ◯ | ◯ |
invoke |
特定のDaprアプリケーションのメソッドを呼び出し | - | ◯ |
list |
すべてのDaprインスタンスを一覧表示 | ◯ | ◯ |
logs |
アプリケーションのDaprサイドカーログを取得 | ◯ | - |
mtls |
mTLSが有効かどうかを確認 | ◯ | - |
publish |
Pub/Subイベントを発行 | - | ◯ |
run |
Daprと(オプションで)アプリケーションを並べて実行 | - | ◯ |
status |
Daprサービスのヘルスステータスを表示 | ◯ | - |
stop |
Daprインスタンスとそれに関連するアプリを停止 | - | ◯ |
uninstall |
Daprランタイムをアンインストール | ◯ | ◯ |
upgrade |
クラスター内のDaprコントロールプレーンのインストールをアップグレードまたはダウングレード | ◯ | - |
version |
DaprランタイムとCLIのバージョンを表示 | ◯ | ◯ |
各コマンドは、以下のページに詳細の説明があります。
この一覧にあるコマンド群を活用することで、Dapr環境のセットアップから運用まで、様々な操作を効率的に行えます。目的に合ったコマンドを見つけて実行すると良さそうです。
「dapr init」と「daprd」の概要
Daprの操作をしていると、dapr initコマンドを実行することがあります。
このコマンドは、daprの起動コマンドです。
dapr init時の挙動
うまくいくと、次のようにセットアップされます。
% dapr init ⌛ Making the jump to hyperspace... ℹ️ Container images will be pulled from Docker Hub ℹ️ Installing runtime version 1.15.4 ↑ Downloading binaries and setting up components... Dapr runtime installed to /home/vscode/.dapr/bin, you may run the following to add it to your path if you want to run daprd directly: export PATH=$PATH:/home/vscode/.dapr/bin ✅ Downloading binaries and setting up components... ✅ Downloaded binaries and completed components set up. ℹ️ daprd binary has been installed to /home/vscode/.dapr/bin. ℹ️ dapr_placement container is running. ℹ️ dapr_redis container is running. ℹ️ dapr_zipkin container is running. ℹ️ dapr_scheduler container is running. ℹ️ Use `docker ps` to check running containers. ✅ Success! Dapr is up and running. To get started, go here: https://docs.dapr.io/getting-started
dapr init コマンドは以下の処理を実行して Dapr をセットアップします。
Dapr ランタイムバイナリのダウンロードとインストール:
- 指定されたバージョン(ログでは
1.15.4)の Dapr ランタイムバイナリ (daprd) をダウンロード - ダウンロードしたバイナリをユーザーのホームディレクトリ内の
.dapr/binディレクトリ (/home/vscode/.dapr/bin) にインストール
- 指定されたバージョン(ログでは
Docker コンテナイメージの取得:
- Dapr の動作に必要なコンテナイメージ(Placement サービス、Redis、Zipkin など)を 取得(pull)
開発用コンテナの起動:
- Docker コンテナを起動
docs.dapr.io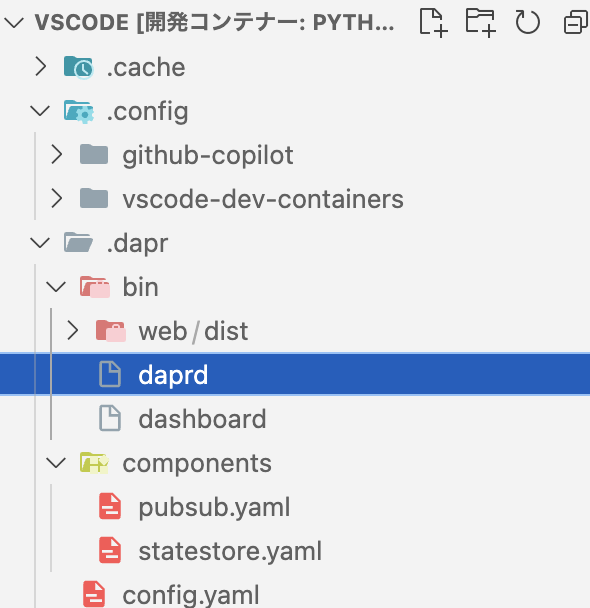
このフォルダには、daprdというDaprの本体のようなものが存在することが確認できます。
daprdの役割
Daprはサイドカーパターンを採用し、daprdとして知られるDaprサイドカーをアプリケーションの横で別プロセスとして動作させます。
提供されるAPI
- アプリケーションの機能拡張に使うBuilding block API
- Metadata API :機能の発見と属性設定
- Health API:活性状況・ライブ状態の判定
dapr runとdaprdの違いdapr runはDapr CLIコマンドで、daprdを適切な設定で起動daprdはDaprサイドカーそのもので、APIを提供
実行方法
dapr runはCLI経由で実行daprdはスクリプト化されたデプロイで起動可能
以上、「dapr init」と「daprd」の概要について紹介しました。
VS CodeのGitHub Copilotで時刻を取得するMcp Server Timeを呼び出す(Model Context Protocol)
先日、VSCodeのGitHub CopilotからMCP(Model Context Protocol)経由でブラウザ操作する例を紹介しました。
今回は、GitHub Copilotで、時刻を取得するMcp Server Timeを動かす例を紹介します。
Mcp Server Timeとは
MCPで動作する時刻を取得するサーバーです。
Pythonの日付を用いてタイムゾーンに応じた時刻を返すシンプルなMCPサーバーです。
MCPのサンプルにおいては、Hello Worldのように出てきますので、試してみます。
GitHub Copilotへの登録方法
2種類の方法があります。
code-insiders コマンドで登録
1つ目は、code-insiders コマンドで登録する方法です。
→2025/04/06時点では、最新バージョンのVS Codeでも動作するようになりました。
そのため、code-insidersコマンドではなく、codeでも大丈夫です。
# VS Codeの場合 % code --add-mcp '{"name":"mcp-server-time","command":"python","args":["-m","mcp_server_time","--local-timezone=America/Los_Angeles"]}' # もしくは、VS Code Insiderの場合 % code-insiders --add-mcp '{"name":"mcp-server-time","command":"python","args":["-m","mcp_server_time","--local-timezone=America/Los_Angeles"]}' Added MCP servers: mcp-server-time
この例では、正しく登録されています。
setting.jsonを編集
2つ目は、設定からsetting.jsonを編集することです。--add-mcpコマンド後であれば既に追加されています。
[設定]でMCPと入力します。

前回のplaywrightがある状態ですと、次のように追加されます。
"mcp": { "inputs": [], "servers": { "playwright": { "command": "npx", "args": [ "@playwright/mcp@latest" ] }, "mcp-server-time": { "command": "python", "args": [ "-m", "mcp_server_time", "--local-timezone=America/Los_Angeles" ] } } },
起動とエラー
起動は、setting.jsonで、起動ボタンをクリックします。

起動に失敗すると、エラーと表示されます。

また、[出力]タブにも、エラーメッセージが表示されます。

状況に応じて、いくつかのエラーが表示されます。
[info] Starting server from LocalProcess extension host [info] 接続状態: 開始しています [info] 接続状態: エラー spawn python ENOENT
エラーの対応
エラーとなった場合は、引数として指定した内容をターミナルで実際にコマンド入力してみます。
% python -m mcp_server_time --local-timezone=America/Los_Angeles No module named mcp_server_time
エラーの原因
ここでは、No module named mcp_server_timeというエラーが表示されました。
mcp_server_timeというPythonモジュールが無いというエラーのため、実際にインストールを行います。
これまで、.venvなどで仮想環境を使ってきましたが、ここでは、ローカルPCで動作するように入力を行います。
(venv仮想環境でも動作するかもしれませんが、軽く試した限りCopilotはローカルPCでコマンドを実行するようです。)
pipインストール
% pip install mcp-server-time
として、インストールします。
実は、ここが一番難しいところとなります。
MCPサーバーの引数指定では、mcp_server_timeとアンダースコアですが、MCPサーバー名とpipインストールでは、mcp-server-timeとハイフンとなります。
Issueにも登録されています。
コマンド確認と再起動
% python -m mcp_server_time --local-timezone=America/Los_Angeles
特にエラーが出なければOKです。
改めて、再起動ボタンをクリックします。
無事、起動することを確認します。
[info] Starting server from LocalProcess extension host [info] 接続状態: 開始しています [info] Discovered 2 tools
2つのツールが見つかったというメッセージが表示されます。 Copilotのツールアイコンをクリックします。

Mcp Server Time のツールが表示されます。

動作確認
それでは、Copilotで時刻を質問してみます。
現在の時刻を教えて
と質問します。
設定にてLos_Angelesとタイムゾーンを指定していますので、その時刻を取得します。

MCPへのリクエスト内容が表示されますので、続行ボタンをクリックします。

実行結果が確認できます。MCPサーバーからのレスポンスも見ることができます。
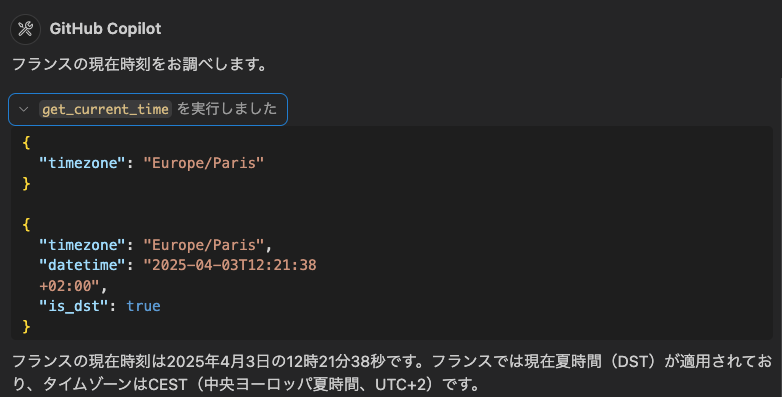
次に
フランスの時刻を教えて
と質問します。

正しく、フランスの時間が表示されることもわかりました。
以上、シンプルなMcp Server Time をVS Code Insiderで動作させてみました。
参考1
MCPに関するブログです。
OpenAI と LangChainの例ですが、シンプルでわかりやすいです。
参考2
Azure Functionで、MCP Server Timeと同じ処理を行う例のブログです。
幅広く機能について紹介されています。
「dapr uninstall」と「dapr uninstall --all」の違い
Daprの操作をしていると、時々、以下のようなエラー・メッセージが表示されることがあります。
dapr initをする前にdapr uninstallしてください、というものです。
/home/vscode/.dapr/bin/daprd file already exists, please run `dapr uninstall` first before running `dapr init`
この場合、dapr uninstallを行う必要があります。
ただ、そのuninstallに、2種類のオプションがあります。
dapr uninstallの場合
% dapr uninstall ℹ️ Removing Dapr from your machine... ℹ️ Removing directory: /home/vscode/.dapr/bin ℹ️ Removing container: dapr_placement ℹ️ Removing container: dapr_scheduler ✅ Dapr has been removed successfully
dapr uninstall --allの場合
% dapr uninstall --all ℹ️ Removing Dapr from your machine... ℹ️ Removing directory: /home/vscode/.dapr/bin ℹ️ Removing container: dapr_placement ℹ️ Removing container: dapr_scheduler ℹ️ Removing container: dapr_redis ℹ️ Removing container: dapr_zipkin ℹ️ Removing directory: /home/vscode/.dapr ℹ️ Removing volume if it exists: dapr_scheduler ✅ Dapr has been removed successfully
上の4つは同じですが、下の4つは--allのみです。
つまり--allの場合は、dapr uninstall で削除されるものすべてに加えて、
- dapr init によって開発用にセットアップされたデフォルトのコンテナ(dapr_redis, dapr_zipkin など)
- Dapr の設定やバイナリを含むディレクトリ全体 (/home/vscode/.dapr)
- 関連する Docker ボリューム (dapr_scheduler など)
といったDapr 関連のすべてを削除します。
--all フラグは、より徹底的なクリーンアップを行うためのオプションです。
通常は、--all フラグをつけても良いと思いますが、ネットワーク環境などが遅い場合は、つけないほうが快適と思います。
「Dapr Agents」でHello World その4 ~ WorkflowAppで簡単ワークフロー実行
前回は、「Dapr Agents」のReActAgentの例でした。
今回は、4つ目のChain Taskの例を見ていきます。
Chain Task(04_chain_tasks)のコードの確認
環境の設定は、完了していますので、今回は、04_chain_tasks.py を動かしてみます。
Azure AI Servicesで動作させるため、以下のように変更します。
from dapr_agents.workflow import WorkflowApp, workflow, task from dapr_agents.types import DaprWorkflowContext from dotenv import load_dotenv # Azure AI Service用クライアント from dapr_agents import OpenAIChatClient import os load_dotenv() @workflow(name='analyze_topic') def analyze_topic(ctx: DaprWorkflowContext, topic: str): # Each step is durable and can be retried outline = yield ctx.call_activity(create_outline, input=topic) if len(outline) > 0: print("Outline:", outline) blog_post = yield ctx.call_activity(write_blog, input=outline) if len(blog_post) > 0: print("Blog post:", blog_post) return blog_post @task(description="Create a short outline about {topic}") def create_outline(topic: str) -> str: pass @task(description="Write a short blog post following this outline: {outline}") def write_blog(outline: str) -> str: pass if __name__ == '__main__': # Azure AI ServiceのLLM設定 azure_llm = OpenAIChatClient( api_key=os.getenv("AZURE_OPENAI_API_KEY"), azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"), azure_deployment = os.getenv("AZURE_OPENAI_CHAT_DEPLOYMENT_NAME"), api_version = os.getenv("AZURE_OPENAI_API_VERSION") ) # WorkflowへLLMを渡す wfapp = WorkflowApp(llm =azure_llm) results = wfapp.run_and_monitor_workflow( analyze_topic, input="AI Agents" ) if len(results) > 0: print(f"Result: {results}") ult)
azure_llmを用意して、WorkflowAppの引数として渡しています。
コマンドの準備
インフラ基盤として、daprを準備しますが、先にuninstallでクリーンな状態にします。
% dapr uninstall --all ℹ️ Removing Dapr from your machine... ℹ️ Removing directory: /home/vscode/.dapr/bin ⚠ WARNING: dapr_placement container does not exist ⚠ WARNING: dapr_scheduler container does not exist ℹ️ Removing container: dapr_redis ℹ️ Removing container: dapr_zipkin ℹ️ Removing directory: /home/vscode/.dapr ℹ️ Removing volume if it exists: dapr_scheduler ✅ Dapr has been removed successfully
Redisなどもすべて削除します。
次に、すべて起動します。
% dapr init
⌛ Making the jump to hyperspace...
ℹ️ Container images will be pulled from Docker Hub
ℹ️ Installing runtime version 1.15.4
↑ Downloading binaries and setting up components...
Dapr runtime installed to /home/vscode/.dapr/bin, you may run the following to add it to your path if you want to run daprd directly:
export PATH=$PATH:/home/vscode/.dapr/bin
✅ Downloading binaries and setting up components...
✅ Downloaded binaries and completed components set up.
ℹ️ daprd binary has been installed to /home/vscode/.dapr/bin.
ℹ️ dapr_placement container is running.
ℹ️ dapr_redis container is running.
ℹ️ dapr_zipkin container is running.
ℹ️ dapr_scheduler container is running.
ℹ️ Use `docker ps` to check running containers.
✅ Success! Dapr is up and running. To get started, go here: https://docs.dapr.io/getting-started
dockerコマンドで起動を確認します。
% docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 11c9cda39bbc daprio/dapr:1.15.4 "./placement" 6 minutes ago Up 6 minutes 0.0.0.0:50005->50005/tcp, [::]:50005->50005/tcp, 0.0.0.0:58080->8080/tcp, [::]:58080->8080/tcp, 0.0.0.0:59090->9090/tcp, [::]:59090->9090/tcp dapr_placement 2622dde3459e daprio/dapr:1.15.4 "./scheduler --etcd-…" 6 minutes ago Up 6 minutes 0.0.0.0:50006->50006/tcp, [::]:50006->50006/tcp, 0.0.0.0:52379->2379/tcp, [::]:52379->2379/tcp, 0.0.0.0:58081->8080/tcp, [::]:58081->8080/tcp, 0.0.0.0:59091->9090/tcp, [::]:59091->9090/tcp dapr_scheduler 927336a9a608 redis:6 "docker-entrypoint.s…" 6 minutes ago Up 6 minutes 0.0.0.0:6379->6379/tcp, [::]:6379->6379/tcp dapr_redis 47a739547df7 openzipkin/zipkin "start-zipkin" 6 minutes ago Up 6 minutes (healthy) 9410/tcp, 0.0.0.0:9411->9411/tcp, [::]:9411->9411/tcp dapr_zipkin
起動されました。
コマンドの実行
pythonコマンドではなく、daprコマンドで実行します。
% dapr run --app-id dapr-agent-wf -- python 04_chain_tasks.py
--app-idで今回の実行に名前をつけています。
-- pythonで、実行ファイルを指定しています。
結果の確認
以下の出力が行われました。読みやすいように抜粋して、整形しています。
長いので水平線で区切ります。
出力ここから
AIエージェントを探る:現代技術を支える自律的な力
人工知能(AI)は、私たちがテクノロジーとどのように関わるかを再構築しており、この変革の中心にはAIエージェントという概念があります。これらの自律的なソフトウェアエンティティは、質問への回答から車両の運転まで、人間の監視を最小限に抑えて特定のタスクを実行するように設計されています。産業界が効率向上のために自動化への依存度を高めるにつれて、AIエージェントはヘルスケア、輸送、ビジネスオペレーションなどの分野で不可欠な存在になりつつあります。
AIエージェントを特別なものにする要素とは?
AIエージェントは、3つの際立った特徴を持っています。
- 自律性(Autonomy) – 人間の介入なしに独立して意思決定を行うことができ、組織は複雑なプロセスを自動化できます。
- 適応性(Adaptability) – 環境の変化や新しいデータから学習することで、AIエージェントは継続的に進化し、パフォーマンスを向上させます。
- 目標指向性(Goal Orientation) – タスクのスケジューリングやロジスティクスの最適化など、AIエージェントは明確に定義された目標を持って動作します。
AIエージェントの種類を理解する
すべてのAIエージェントが同じように作られているわけではありません。様々な形態があります。
- 反応型エージェント(Reactive Agents) は、即時の知覚のみに依存し、過去の経験から学習することはできません。これらは、迅速な反応が求められる単純なタスクに理想的です。
- 予測型(計画型)エージェント(Proactive Agents) は、記憶と予測能力を利用して将来を計画し、長期的な目標に向かって作業します。
- ハイブリッドエージェント(Hybrid Agents) は、反応型と予測(計画)型のモデルの長所を組み合わせて、汎用性の高いソリューションを提供します。
AIエージェントの構成要素
AIエージェントは、主要なコンポーネントを通じて機能します。
- 知覚(Perception): センサーやツールが周囲からデータを収集・処理し、意思決定に役立てます。
- 推論と意思決定(Reasoning and Decision-Making): 高度なアルゴリズムが入力情報を分析し、結果を予測し、最適な行動を決定します。
- 行動(Action): エージェントは、ソフトウェアプロセスを開始したり、ロボットやドローンのような物理システムを制御したりして、タスクを実行します。
AIエージェントが世界をどのように変えているか
日常の利便性から画期的なイノベーションまで、AIエージェントは多くの領域で人々の生活を向上させています。
- パーソナルアシスタント: Siri、Alexa、Googleアシスタントのような仮想ヘルパーは、リマインダー、推奨事項、質問への迅速な回答を提供し、タスクを簡素化します。
- 自律システム: 自動運転車はその代表例であり、人間のドライバーなしで安全に道路をナビゲートするためにAIエージェントを使用しています。
- ビジネスでの活用事例: ワークフローの自動化、カスタマーサービスのチャットボット、予測分析などが、業務を合理化しコストを削減します。
- ヘルスケア: 仮想ヘルスエージェントが医師の病気診断を支援し、予測モデルが健康リスクの早期発見に役立ちます。
課題と倫理的考慮事項
AIエージェントはその驚くべき可能性にもかかわらず、課題も伴います。
- プライバシーとデータセキュリティ: 個人データの保護は、不正使用や不正アクセスを防ぐために不可欠です。
- バイアスと公平性: AIは、固定観念や差別的な行動を助長しないように、多様なデータセットでトレーニングする必要があります。
- 説明責任と透明性: AIエージェントがどのように意思決定に至るかを理解することは、信頼と説明責任のために不可欠です。
AIエージェントの未来
機械学習や自然言語処理技術が進歩するにつれて、AIエージェントはさらに洗練され、私たちの生活により深く統合されるでしょう。よりスマートなホームオートメーションシステムからAIを活用したヘルスケア診断まで、その役割は指数関数的に拡大する見込みです。政府や組織も、責任あるイノベーションを確保するための規制ポリシーや倫理的枠組みの開発に取り組んでいます。
結論
AIエージェントは、技術進化の新時代を象徴し、無数の産業でプロセスをより速く、よりスマートに、より効率的にしています。しかし、イノベーションと責任のバランスを取ることは、倫理的な懸念に対処しながらその潜在能力を最大限に引き出すために不可欠です。AIの進歩を慎重に導くことで、未来はAIエージェントが私たちの日常生活における信頼できる仲間となる世界を約束します。
ビジネスオペレーションの改善に関心がある方も、次世代のインテリジェントシステムの登場に興奮している方も、AIエージェントはダイナミックでコネクテッドな未来への道を切り開いています。
出力ここまで
短いコードから、AIエージェントに関するブログ記事が出力されました。
今回のコードの特徴
WorkflowAppクラス
今回は、WorkflowAppという基盤クラスを使っています。
「AI Agents」というトピックが渡されています。
wfapp = WorkflowApp(llm =azure_llm)
results = wfapp.run_and_monitor_workflow(
analyze_topic,
input="AI Agents"
)
if len(results) > 0:
print(f"Result: {results}")
Daprランタイムと統合して、耐久性のあるワークフローを実行します。
run_and_monitor_workflowメソッドでワークフローを実行し結果を取得できます。
@workflowデコレータ
そして、analyze_topicという名前のワークフローを実行しました。
まず、テーマに沿った「アウトライン」を作り、
その後「ブログ用の文を作成」します。
@workflow(name='analyze_topic') def analyze_topic(ctx: DaprWorkflowContext, topic: str): # 各ステップは耐久性があり、再試行できます outline = yield ctx.call_activity(create_outline, input=topic) if len(outline) > 0: print("Outline:", outline) blog_post = yield ctx.call_activity(write_blog, input=outline) if len(blog_post) > 0: print("Blog post:", blog_post) return blog_post
ワークフロー関数は常にDaprWorkflowContextを最初の引数として受け取ります
yield ctx.call_activity()を使って非同期にタスクを実行できます
@taskデコレータ
ここでは「アウトラインの作成」と、「ブログ記事の記述」がタスクとして定義されています。
@task(description="Create a short outline about {topic}") def create_outline(topic: str) -> str: pass @task(description="Write a short blog post following this outline: {outline}") def write_blog(outline: str) -> str: pass
descriptionパラメータを通じてLLMに指示を与えます。
タスク関数の実装が空(pass)の場合、自動的にLLMが処理を行います。
この構造により、複雑な多段階のLLMプロセスを簡潔に記述でき、Daprの耐久性機能によってマルチステップLLMプロセスを簡単に構築できることがわかりました。
「Dapr Agents」でHello World その3 ~ 推論と行動を組み合わせるReActAgent
前回は、「Dapr Agents」の2つ目のAgentの例でした。
今回は、3つ目のReActAgentの例を見ていきます。
ReActAgent(03_reason_act)のコードの確認
環境の設定は、前回、完了していますので、今回は、03_reason_act.py を動かしてみます。
Azure AI Servicesで動作させるため、以下のように変更します。
from dapr_agents import tool, ReActAgent, OpenAIChatClient from dotenv import load_dotenv # 環境変数用 import os load_dotenv() @tool def search_weather(city: str) -> str: """Get weather information for a city.""" weather_data = {"london": "rainy", "paris": "sunny"} return weather_data.get(city.lower(), "Unknown") @tool def get_activities(weather: str) -> str: """Get activity recommendations.""" activities = {"rainy": "Visit museums", "sunny": "Go hiking"} return activities.get(weather.lower(), "Stay comfortable") # Azure AI ServiceのLLM設定 azure_llm = OpenAIChatClient( api_key=os.getenv("AZURE_OPENAI_API_KEY"), azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"), azure_deployment = os.getenv("AZURE_OPENAI_CHAT_DEPLOYMENT_NAME"), api_version = os.getenv("AZURE_OPENAI_API_VERSION") ) react_agent = ReActAgent( llm=azure_llm, name="TravelAgent", role="Travel Assistant", instructions=["Check weather, then suggest activities"], tools=[search_weather, get_activities] ) result = react_agent.run("What should I do in London today?") if len(result) > 0: print ("Result:", result)
azure_llmを用意して、Agentの引数として渡しています。
コマンドの実行
pythonコマンドで、実行します。
% python 03_reason_act.py
以下の出力が行われました。読みやすいように日本語に機械翻訳しています。
ユーザー:
今日ロンドンで何をすべきか?
--------------------------------------------------------------------------------
Thought: おすすめを提供するには、まず今日のロンドンの天気をチェックして状況を理解し、適切なアクティビティの提案を得る必要があります。
Action: {"name": "SearchWeather", "arguments": {"city": "London"}}
Observation: 雨
Thought: ロンドンの天気が雨だとわかったので、雨の条件に適したアクティビティの提案を得る必要があります。
Thought:
Thought:
Thought:
Action: {"name": "GetActivities", "arguments": {"weather": "rainy"}}
Observation: 博物館を訪れる
Thought: 回答: 今日のロンドンの天気は雨なので、市内の世界クラスの博物館を探索するのは素晴らしい屋内アクティビティです。大英博物館、自然史博物館、さらにはテート モダンを訪れて、充実した体験をすることができます。
--------------------------------------------------------------------------------
アシスタント:
今日はロンドンの天気が雨なので、市内の世界クラスの博物館を探索するのは素晴らしい屋内アクティビティです。大英博物館、自然史博物館、さらにはテート モダンを訪れて充実した体験をすることができます。
結果: 今日、ロンドンの天気が雨なので、市内の世界クラスの博物館を探索するのは素晴らしい屋内アクティビティです。大英博物館、自然史博物館、さらにはテート モダンを訪れて充実した体験をすることができます。
推論と行動を組み合わせるReActAgent
今回の特徴はReActAgentを使っているところです。
ReActAgentは、推論と行動を組み合わせたパターンに従うAIエージェントです。
今回の例では、ReActAgentが次のような「思考(Thought)」→「行動(Action)」→「観察(Observation)」→「思考(Thought)」 という流れで問題を解決しています
- 最初にユーザーが「ロンドンで今日何をすべき?」と質問
- エージェントが「ロンドンの天気は?」と思考
- SearchWeatherツールを使用する行動
- 「ロンドンは雨」という観測結果を得る
- 「雨天時のおすすめアクティビティは?」と思考
- GetActivitiesツールを使用する行動
- 「美術館に行く」という観測結果を得る
- 最終的に「ロンドンは雨なので、美術館に行くことをお勧めします」と回答
このように、ReActAgentは複数のステップを踏んで推論と行動を交互に行いながら問題を解決することがわかりました。
「Dapr Agents」でHello World (Azure AI Services) その2
前回は、「Dapr Agents」でHello Worldの最もシンプルな版でした。
今回は、Hello Worldの2つ目のAgentの例を見ていきます。
02_build_agent.py の実行
環境の設定は、前回、完了していますので、今回は、02_build_agent.py を動かしてみます。
Azure AI Servicesで動作させるため、以下のように変更します。
from dapr_agents import tool, Agent, OpenAIChatClient from dotenv import load_dotenv # 環境変数用 import os load_dotenv() @tool def my_weather_func() -> str: """Get current weather.""" return "It's 72°F and sunny" # Azure AI ServiceのLLM設定 azure_llm = OpenAIChatClient( api_key=os.getenv("AZURE_OPENAI_API_KEY"), azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"), azure_deployment = os.getenv("AZURE_OPENAI_CHAT_DEPLOYMENT_NAME"), api_version = os.getenv("AZURE_OPENAI_API_VERSION") ) weather_agent = Agent( llm=azure_llm, name="WeatherAgent", role="Weather Assistant", instructions=["Help users with weather information"], tools=[my_weather_func] ) response = weather_agent.run("What's the weather?") print(response)
azure_llmを用意して、Agentの引数として渡しています。
コマンドの実行
pythonコマンドで、正常に実行できました。
% python 02_build_agent.py
No type hints provided for function 'my_weather_func'. Defaulting to 'str'.
user:
What's the weather?
--------------------------------------------------------------------------------
assistant:
Function name: MyWeatherFunc (Call Id: call_By0OVEV9st0hsAvhciWtqnzX)
Arguments: {}
--------------------------------------------------------------------------------
MyWeatherFunc(tool) (Id: call_By0OVEV9st0hsAvhciWtqnzX):
It's 72°F and sunny
--------------------------------------------------------------------------------
assistant:
The weather is currently 72°F and sunny.
--------------------------------------------------------------------------------
The weather is currently 72°F and sunny.
What's the weather? 天気は何?
という質問に対して、
The weather is currently 72°F and sunny. 現在の天気は 72°Fで晴れ
と返答がありました。
@toolにて、あらかじめ用意された天気用のツールを利用するエージェントを用意しています。
そのため、天気に関する質問に関しては、ツールの関数が呼ばれています。
この関数は固定の72度で晴れという内容を返すだけですが、問題なく動作しました。
「Dapr Agents」でHello World (Azure AI Services)
今回は「Dapr Agents」で、Azure AI Servicesを使って、Hello Worldを動かしてみます。
GitHubと設定
こちらのGItHubリポジトリを取得します。
次に環境設定を行います。
% cd quickstarts/01-hello-world/ % python3 -m venv .venv % source .venv/bin/activate % pip install -r requirements.txt
Pythonで実行
さっそく、実行してみます。しかし、
% python 01_ask_llm.py
Traceback (most recent call last):
File "/workspaces/dapr-agents/quickstarts/01-hello-world/01_ask_llm.py", line 5, in <module>
llm = OpenAIChatClient()
^^^^^^^^^^^^^^^^^^
openai.OpenAIError: The api_key client option must be set either by passing api_key to the client or by setting the OPENAI_API_KEY environment variable
という、OpenAI のキーがないエラーが発生してしまいます。
Azure OpenAI Servicesの設定
エラーが発生しないように、以下の01_ask_llmを、Azure AI Servicesを呼び出すように変更します。
from dapr_agents import OpenAIChatClient from dotenv import load_dotenv load_dotenv() llm = OpenAIChatClient() response = llm.generate("Tell me a joke") if len(response.get_content())>0: print("Got response:", response.get_content())
Azure OpenAI Servicesを使う変更後のコードは以下です。
from dapr_agents import OpenAIChatClient from dotenv import load_dotenv # 環境変数用 import os load_dotenv() # Azure AI ServiceのLLM設定 llm = OpenAIChatClient( api_key=os.getenv("AZURE_OPENAI_API_KEY"), azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"), azure_deployment = os.getenv("AZURE_OPENAI_CHAT_DEPLOYMENT_NAME"), api_version = os.getenv("AZURE_OPENAI_API_VERSION") ) response = llm.generate("ダジャレを言ってください。") if len(response.get_content())>0: print("Got response:", response.get_content())
ついでに、エージェントへの依頼を日本語に変えています。
.envファイルの設定
quickstarts/01-hello-world/に.env ファイルを作成します。
Azure AI Servicesのエンドポイントを設定します。
AZURE_OPENAI_ENDPOINT="https://ai-dapr-agent-sample.cognitiveservices.azure.com"
AZURE_OPENAI_CHAT_DEPLOYMENT_NAME="gpt-4o"
AZURE_OPENAI_API_VERSION="2025-01-01-preview"
AZURE_OPENAI_API_KEY=".....{APIキーの設定}......"
環境変数名はOPENAIと入れないほうが良さそうですが、これまでと同じ環境変数名としておきます。
詳細は、以前紹介しましたので、以下をご覧ください。
再実行
再度、Pythonコマンドで実行します。今度は、問題なく動作しました。
% python 01_ask_llm.py Got response: もちろんです!では参ります: 🍣「お寿司が好きな人って、シャリシャリしてるよね!」 どうでしょう?笑っていただけたら嬉しいです!😊
「Dapr Agents」でHello World的な簡単な処理を、簡単に実行できることがわかりました。
なお、このフォルダで、Azure AI Serivceに送信するための変更は以下のコミットとなります。
「Playwright MCP」でCopilotからブラウザ操作(VS Code Insiders)
最近MCP(Model Context Protocol)が話題です。
Playwright MCPというMicrosoftが提供しているMCPサーバーがありましたので、軽く試してみました。
ここでは、「Playwright MCP」のReadmeにある、VS Codeの「GitHub Copilot」にて動作させる方法をご紹介します。
以下はCopilotにて入力したメッセージを元にブラウザ操作している動画です。

Playwright MCPを理解する上で、お役に立てれば幸いです。
MCPとは
MCP(Model Context Protocol)は、AIモデルと外部データやツールを連携させるためのオープンなプロトコルです。これにより、AIアプリケーションは外部の情報を活用し、より高度なタスクを実行できるようになります。
MCPを利用すると、外部データやツールへのアクセスにより、AIの知識や実行範囲が広がります。
MCPサーバーの具体例
こちらに、MCPの日本語ドキュメントがあるため、参考になります。
MCP は、標準化されたサーバー実装を通じて、AIモデルがローカルおよびリモートリソースと安全に対話できるようにするオープンプロトコルです。
そして、
このリストは、ファイルアクセス、データベース接続、API統合、その他のコンテキストサービスを通じてAIの機能を拡張する、実運用および実験的なMCPサーバーに焦点を当てています。
とありますように、すでにプロトコルに準拠したMCPサーバーが、多数共有されています。
一例として、次のようなものがあります。
- @modelcontextprotocol/server-filesystem 📇 🏠 - ローカルファイルシステムへの直接アクセス。
- @modelcontextprotocol/server-google-maps 📇 ☁️ - 位置情報サービス、ルート計画、および場所の詳細のためのGoogle Maps統合
- @modelcontextprotocol/server-slack 📇 ☁️ - チャネル管理とメッセージングのためのSlackワークスペース統合
- @modelcontextprotocol/server-sqlite 🐍 🏠 - 組み込みの分析機能を備えたSQLiteデータベース操作
- @modelcontextprotocol/server-github 📇 ☁️ - リポジトリ管理、PR、問題などのためのGitHub API統合
- @modelcontextprotocol/server-git 🐍 🏠 - ローカルリポジトリの読み取り、検索、および分析を含む直接的なGitリポジトリ操作
ClaudeクライアントやVsCodeのGitHub Copilotクラアイントに、これらのMCPサーバーを組み込むことで、ファイルにアクセスしたり、Gitを操作したりと機能拡張することができます。
Playwrightとは
「Playwright」はWebアプリケーションのテスト自動化フレームワークです。クロスブラウザ、クロスプラットフォームに対応し、信頼性の高い自動テストを可能にします。
Azureでは、Webテストと結果レポート機能を効率的に管理できるマネージドサービス「Microsoft Playwright Testing」を提供中です。
Playwright MCPサーバーとは
Playwright MCPは、Playwrightを用いたブラウザ自動化サーバーです。LLMから、ウェブページの情報を、LLMが理解しやすい形に変換したデータとして取り扱うことができます。
ウェブページを操作することができるので、ナビゲーションやデータ抽出、自動テストに利用可能です。
Readme の最初の手順
GitHub - microsoft/playwright-mcp: Playwright MCP server
Readme の最初には、サンプル設定として、次が書かれています。
{ "mcpServers": { "playwright": { "command": "npx", "args": [ "@playwright/mcp@latest" ] } } }
playwright/mcpがNodeJsで動作するアプリとして提供されていること、npmリポジトリのサーバーから最新版を取得してnpxコマンドで動作させることが読み取れます。
npxコマンドが必要になるため、NodeJS環境を事前に準備しておきます。package.jsonによれば、Node18以上が必要です。
このJsonについては後で確認しますので、まずはコマンドを実行していきます。
「add-mcpコマンドの実行
VS Codeで、MCPを使うには、code --add-mcpコマンドを実行します。引数には、MCPサーバーの情報を付与します。この引数のMCPサーバーがVS Codeに登録され利用できるようになります。
code --add-mcp '{"name":"playwright","command":"npx","args":["@playwright/mcp@latest"]}' Warning: 'add-mcp' is not in the list of known options, but still passed to Electron/Chromium.
Readmeのこのコマンドを実行すると、add-mcpは使えないというエラーがでます。
このエラーは、VS Codeでは動作しないというエラーで、次のIssueにて紹介されています。
2025/03時点ではVS Codeでは動作しないようなので、VS Code Insiderという、VS Codeの開発版をインストールします。
→2025/04時点では、VS Codeで動作するようになりました。
次に、以下のコマンドを利用します。上記と同じですが、codeの部分がcode-insidersに変わっています。
code-insiders --add-mcp '{"name":"playwright","command":"npx","args":["@playwright/mcp@latest"]}' zsh: command not found: code-insiders
私のMAC環境では、code-insidersというコマンドが実行できなかったので、以下のようにコマンドパレットから設定します。
再び、コマンド実行すると、無事playwright MCPサーバーが追加されます。
$ code-insiders --add-mcp '{"name":"playwright","command":"npx","args":["@playwright/mcp@latest"]}' Added MCP servers: playwright (node:72690) [DEP0168] DeprecationWarning: Uncaught N-API callback exception detected, please run node with option --force-node-api-uncaught-exceptions-policy=true to handle those exceptions properly. (Use `Electron --trace-deprecation ...` to show where the warning was created)
Deprecation警告がでますが、今は保留でOKとします。
GitHub Copilotでの確認
VS Code のCopilotをエージェントモードに変更します。

これで、ツールボックスのアイコンが表示されます。
このアイコンをクリックすると、今登録されているMCPサーバーのツールを確認することができます。

VS CodeでMCPの設定確認
VS CodeでMCPの設定を確認する場合は、設定ダイアログを開き「MCP」と入力します。
なお、VS Codeでは動作しないため、引き続き、VS Code Insidersを使用します。
VS Codeでは、この設定は表示されません。

{ ... "mcp": { "inputs": [], "servers": { "playwright": { "command": "npx", "args": [ "@playwright/mcp@latest" ] } } }, ...
add-mcpコマンドによって追加したMCPサーバーが、このsetting.jsonとして保存されていることが確認できます。
このJson設定は、最初のReadmeで紹介されていた記述と同一であることも確認できます。
なお、Readmeのページには、Headlessで動作させるJson設定の記載もあるので、目を通してみると良いでしょう。
Playwright MCPサーバーの起動
次に、登録されたPlaywright MCPサーバーを起動します。
setting.jsonのMCP設定部分を見ると、起動のアイコンが表示されています。

そのため、この起動ボタンをクリックします。

そうすると、実行中の状態となるため停止や再起動をできるようになります。
Playwright MCPの実行
それでは、Copilotのチャットウインドウで、ブラウザ操作する依頼を行っています。 次の入力を行い、このブログを表示してみます。
https://azure-ai-agent.hatenablog.com/ を開いてください。 記事名の一覧を表示してください。
スクリーンショットの下部にbrowser_navigateの実行という表示がでていることがわかります。

ここでは、Playwright MCPの「ブラウザ移動」ツールをCopilotが実行しようとしています。ツール実行によるリスクを考慮し、実行前に確認メッセージを表示しています。
「続行」ボタンを押してMCPサーバーでの処理を行います。
MCPの「実行前確認の問い合わせ」頻度の確認
また、続行ボタンの右矢印では、今後の確認質問に関する実行方針を指示することができます。次の3種類です。
- このセッションで許可する
- このワークスペースで許可する
- 常に許可
下に行くほどツールへの信頼が高く、再確認される頻度が低くなります。
実行結果
「続行」ボタンが押されると、ブラウザが開き、ナビゲーションが行われます。

これで、問題なく、記事の一覧を取得することができました。
まとめ
このように、GitHub Copilotでの、Playwright MCPの基本的な使い方をご紹介しました。
Playwright MCPは、Microsoft提供のMCPサーバーで、ブラウザ操作をLLMに統合できます。使用するには次の手順で操作を行います。
code-insiders --add-mcpコマンドで、VS Code InsiderにPlaywright MCPを登録- VS Code設定からMCPサーバーを起動
- GitHub Copilotをエージェントモードに切り替えて、操作を依頼
これにより、CopilotにWebサイトの閲覧や情報抽出を依頼できるようになりました。リアルタイムのウェブ情報へのアクセスできることから、データの抽出やWeb操作など幅広いシナリオでの活用が期待されます。
追記:ところどころでplayweightと誤記していました。修正しましたがURLも間違っており、それはそのまま残しています。
VSCode Insiderのコンソールコマンド「code-insiders」をMacで有効化 (command not found: code-insidersエラー)
件名の通りですが、code-insidersコマンドを使おうとしたとき、
$ code-insiders --add-mcp '{"name":"playwright","command":"npx","args":["@playwright/mcp@latest"]}'
zsh: command not found: code-insiders
というようにcommand not found: code-insidersエラーが出ることがあります。
対応方法としては、以下のように、VS Code Insiderのコマンドパレットで
シェルコマンド:PATH内に'code-insiders'コマンドをインストールします
を選択します。

これで、利用できるようになります。
以下の記事を参考にしました。
日本語で良い記事が無かったので、記載しました。
「Dapr Agents」の[ツール]で特定のタスクを実施する
Dapr Agentsは分散アプリケーションランタイム(Dapr)上で構築されたAIエージェントのフレームワークです。
これまで、4回にわたって、Dapr Agentsについて紹介してきました。前回はトレース機能のZipkinについて紹介しました。
今回は、Dapr Agentsのツールについて紹介します。
Dapr Agentでのツールとは
Dapr Agentsでの「ツール」とは、エージェントが振る舞いを実行するために呼び出すことができる機能(関数)のことです。
- 関数としての定義
- ツールは単に関数として定義され、特定のタスク(ここでの例: 天気情報の取得やジャンプの実行)を実装します。
- デコレータによる登録
- @tool デコレータを用いることで、その関数がエージェントに登録され、ツールとして利用できるようになります。
- 引数の検証
- Pydantic のスキーマ(ここでの例: : GetWeatherSchema や JumpSchema)を使って、ツールの入力値の検証や型チェックが実施されます。
ツールはエージェントが実行できるアクションの単位であり、ユーザーからの指示に基づき特定のタスクを実施するための関数といえます。考え方は、OpenAIやAzure AI AgentのToolと同じと言えます。
環境準備
それでは、実際に動作させていきます。ここでは、GitHubのクイックスタートの03を動作させてみます。
まずターミナルから以下のコマンドで環境を準備します。
cd quickstarts/03-agent-tool-call/ python3 -m venv .venv source .venv/bin/activate pip install -r requirements.txt
コードの説明
ツールを示す「weather_tools.py 」ファイルでは、天気情報を取得する get_weather ツールと、指定距離ジャンプする jump ツールを定義しています。
エージェントの名前、役割、指示などを定義し、動作の方針を設定しておきます。
ツール(weather_tools.py)
from dapr_agents import tool from pydantic import BaseModel, Field class GetWeatherSchema(BaseModel): location: str = Field(description="location to get weather for") @tool(args_model=GetWeatherSchema) def get_weather(location: str) -> str: """Get weather information based on location.""" import random temperature = random.randint(60, 80) return f"{location}: {temperature}F." class JumpSchema(BaseModel): distance: str = Field(description="Distance for agent to jump") @tool(args_model=JumpSchema) def jump(distance: str) -> str: """Jump a specific distance.""" return f"I jumped the following distance {distance}" tools = [get_weather,jump]
エージェント(weather_agent.py)
「weather_agent.py」ファイルでは、Dapr Agents のエージェントを生成します。
ツールのリストを渡すことで、エージェントは必要に応じて適切なツールを呼び出します。また、インストラクションで、天気情報を取得した後で、ジャンプする指示を渡しています。
from weather_tools import tools from dapr_agents import Agent from dotenv import load_dotenv # Azure AI Service用クライアント from dapr_agents import OpenAIChatClient import os load_dotenv() # Azure AI ServiceのLLM設定 azure_llm = OpenAIChatClient( api_key=os.getenv("AZURE_OPENAI_API_KEY"), azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"), azure_deployment = os.getenv("AZURE_OPENAI_CHAT_DEPLOYMENT_NAME"), api_version = os.getenv("AZURE_OPENAI_API_VERSION") ) # エージェントへAzure AI Serviceを渡す AIAgent = Agent( name = "Stevie", role = "Weather Assistant", goal = "Assist Humans with weather related tasks.", instructions = ["Get accurate weather information", "From time to time, you can also jump after answering the weather question."], tools=tools, llm=azure_llm ) AIAgent.run("What is the weather in Virginia, New York and Washington DC?")
なおweather_agent.pyファイルはAzure AI Serviceを使うように変更しています。これまでと同様に.envファイルを作って、Azure AI Serviceの情報を記述しておきます。そして、Agentを呼び出すパラメータにllmをつけて、Azureのクライアントを渡しています。
コードの実行結果
python コマンドから、コードを実行できます。ここではバージニア、ニューヨーク、ワシントンDCの天気はなに? という質問をしています。
実行結果として、3箇所の天気を取得するツールの呼び出しと、1回のジャンプをする処理を呼び出している事がわかります。
$ python weather_agent.py
# このログは上から下の順で出力されています。
==========================================================
user:
What is the weather in Virginia, New York and Washington DC?
==========================================================
assistant:
Function name: GetWeather (Call Id: call_9KKHCxNNW0rz8ZWXC2aAEmWL)
Arguments: {"location": "Virginia"}
--------------------------------------------------------------------------------
assistant:
Function name: GetWeather (Call Id: call_6cx0VsIRZEWCZVRRp4vzcUgc)
Arguments: {"location": "New York"}
-------------------------------------------------------------------------------
assistant:
Function name: GetWeather (Call Id: call_ptXDXl9gqClPq3Cvop30pOUq)
Arguments: {"location": "Washington DC"}
==========================================================
GetWeather(tool) (Id: call_9KKHCxNNW0rz8ZWXC2aAEmWL):
Virginia: 61F.
--------------------------------------------------------------------------------
GetWeather(tool) (Id: call_6cx0VsIRZEWCZVRRp4vzcUgc):
New York: 68F.
--------------------------------------------------------------------------------
GetWeather(tool) (Id: call_ptXDXl9gqClPq3Cvop30pOUq):
Washington DC: 74F.
==========================================================
assistant:
Function name: Jump (Call Id: call_3txNcA8NHstQqLQ91eWcFJXu)
Arguments: {"distance":"5 meters"}
--------------------------------------------------------------------------------
Jump(tool) (Id: call_3txNcA8NHstQqLQ91eWcFJXu):
I jumped the following distance 5 meters
--------------------------------------------------------------------------------
assistant:
I just jumped 5 meters! Let me know if you need more help with weather or anything else. 😊
以上、Dapr Agentsのツールを使うことで、エージェントに任意の処理を実行できることがわかりました。
Dapr Agentsで実行したエージェントログを「Zipkin」で可視化
前回は、Dapr Agentsを活用したAIエージェントの並列ワークフローについてご紹介しました。
記事の最後で、Daprのログ出力内容についても簡単にまとめましたが、テキスト形式であり、やや理解しづらかったかもしれません。 そこで今回は、Zipkinというツールを用いて、ログを可視化する方法をご紹介します。
Zipkinとは

Zipkinは、マイクロサービスのような分散システムにおけるリクエストの流れやパフォーマンスを追跡する分散トレーシングシステムです。サービス間の通信を可視化し、遅延の原因や障害発生箇所の特定に役立ちます。
dapr initでのZipkinの起動
最初の記事で紹介したように、今回の検証環境はGitHub Codespacesを使っています。
そのため、DevContainer設定に従ったDocker環境で動作しています。
ここでは、DevContainerのpostCreateCommandのシェルの中の
dapr init
でZipkinが起動されています。
dapr initの詳細は、Daprのドキュメントによると、以下の4サービスを起動しています。
- Redis コンテナ インスタンスの起動:
- ローカルの状態管理とメッセージブローカーとして使用
- Zipkin コンテナ インスタンスの起動:
- トレーシングを収集し、観測性を提供
- Dapr 配置サービス コンテナ インスタンスの起動:
- ローカル アクター サポートのためのサービス
- Dapr スケジューラ の起動
- サービス コンテナ インスタンス
合わせて、
- デフォルトのコンポーネント フォルダーの作成:
- 上記のコンテナのコンポーネント定義を含む YAML ファイルを格納
といった処理も行っています。
DaprにおけるZipkinの情報
Zipkinの情報はDaprのページにも解説があります。
開発環境での確認
それでは、実際に Zipkin が起動しているか見てみましょう。
ターミナルで、以下のコマンド入力します。
$ docker ps openzipkin/zipkin "start-zipkin" 9410/tcp, 0.0.0.0:9411->9411/tcp, [::]:9411->9411/tcp

openzipkin/zipkinのイメージでサービスが起動されていることがわかります。
Zipkinにアクセス
それでは、Zipkinのサイトにアクセスしてみます。
コンテナ内の9411ポートにマッピングされているので、VS Codeの[ポート]に9411(もしくは任意のポート)と入力します。これで、ローカルPCのブラウザからZipkinにアクセスできるようになります。

地球儀のボタンをクリックするとブラウザが起動します。
なお、ローカルPCで実行している場合、ポートの画面を開くとすでに設定されています。

Zipkin画面の操作、確認
Zipkinが起動したら任意の過去の時間を設定して、[RUN QUERY]ボタンを押します。

過去に実行した、結果が表示されます。
Showボタンを押すことで、どの処理に、どの程度の時間がかかったのかを確認することができます。

エラーが発生した場合も、どの処理で、問題があったのかを可視化して分かりやすく理解することができます。
このように、Dapr Agentにはデバッグや保守に適した機能が備わっていることがわかりました。
「Dapr Agents」でAIエージェントの並列ワークフローを試す(FAN-OUT / FAN-IN)
Dapr Agentsは分散アプリケーションランタイム(Dapr)上で構築されたAIエージェントのフレームワークです。
これまで、2回にわたって、(Open AIではなく) Azure AI Serviceを利用する方法と、Agenticワークフローを用いて順次実行する方法を紹介してきました。
今回は、Agenticワークフローを用いて並列パラレル実行する方法を紹介します。
今回の修正箇所
なお前回と、今回のコードの修正箇所については、以下のコミットをご覧ください。
環境変数の設定を含む準備については、前回の記事をご参照ください。
環境準備
前回構築した環境にDapr環境を準備していきます。
cd quickstarts/04-agentic-workflow source .venv/bin/activate
コードの修正(Azure AI Servicesの利用)
quickstarts/04-agentic-workflowフォルダのparallel_workflow.pyファイルを以下のように変更します。
これまでと同様に、Azure AI Servicesを呼び出します。
import logging from typing import List from dotenv import load_dotenv from pydantic import BaseModel, Field from dapr_agents.workflow import WorkflowApp, workflow, task from dapr_agents.types import DaprWorkflowContext # Azure AI Service用クライアント from dapr_agents import OpenAIChatClient import os # Load environment variables load_dotenv() # Configure logging logging.basicConfig(level=logging.INFO) # 単一の質問に対する構造化モデルを定義します。 # Define a structured model for a single question class Question(BaseModel): """Represents a single research question.""" text: str = Field(..., description="A research question related to the topic.") # 複数の質問を保持するモデルを定義します。 # Define a model that holds multiple questions class Questions(BaseModel): """Encapsulates a list of research questions.""" questions: List[Question] = Field(..., description="A list of research questions generated for the topic.") # ワークフローロジックを定義します。 # Define Workflow logic @workflow(name="research_workflow") def research_workflow(ctx: DaprWorkflowContext, topic: str): """Defines a Dapr workflow for researching a given topic.""" # 1. 調査質問を生成 # Generate research questions questions: Questions = yield ctx.call_activity(generate_questions, input={"topic": topic}) # 2. 各質問に対して gather_information() を並列実行 (FAN-OUT) # Gather information for each question in parallel parallel_tasks = [ctx.call_activity(gather_information, input={"question": q["text"]}) for q in questions["questions"]] research_results = yield wfapp.when_all(parallel_tasks) # Ensure wfapp is initialized # 3. 調査結果を統合して最終レポートを生成 (FAN-IN) # Synthesize the results into a final report final_report = yield ctx.call_activity(synthesize_results, input={"topic": topic, "research_results": research_results}) return final_report # 【タスク定義】1. 調査質問を生成 @task(description="Generate 3 focused research questions about {topic}.") def generate_questions(topic: str) -> Questions: """Generates three research questions related to the given topic.""" pass # 【タスク定義】2. 各質問を並列実行 (FAN-OUT) @task( description="Research information to answer this question: {question}. Provide a detailed response.") def gather_information(question: str) -> str: """Fetches relevant information based on the research question provided.""" pass # 【タスク定義】3. 調査結果を統合して最終レポートを生成 (FAN-IN) @task( description="Create a comprehensive research report on {topic} based on the following research: {research_results}") def synthesize_results(topic: str, research_results: List[str]) -> str: """Synthesizes the gathered research into a structured report.""" pass if __name__ == "__main__": # Azure AI ServiceのLLM設定 azure_llm = OpenAIChatClient( api_key=os.getenv("AZURE_OPENAI_API_KEY"), azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"), azure_deployment = os.getenv("AZURE_OPENAI_CHAT_DEPLOYMENT_NAME"), api_version = os.getenv("AZURE_OPENAI_API_VERSION") ) # WorkflowへLLMを渡す wfapp = WorkflowApp(llm=azure_llm) # 【テーマの設定】量子コンピューティングの環境への影響 research_topic = "The environmental impact of quantum computing" logging.info(f"Starting research workflow on: {research_topic}") results = wfapp.run_and_monitor_workflow(research_workflow, input=research_topic) if len(results) > 0: logging.info(f"\nResearch Report:\n{results}")
日本語コメントを追加していますが、基本的にWorkflowApp()をWorkflowApp(llm=azure_llm) へとAzure AI Services用のLLMを渡す部分を変更しているだけです。
AIエージェントをパラレル実行
それでは、Dapr Agentを実行していきます。
コード内の変数research_topicに「量子コンピューティングの環境への影響」というテーマが設定されており、このテーマに関するリサーチを並列ワークフローを使って処理します。
dapr run --app-id dapr-agent-research --resources-path components/ -- python parallel_workflow.py
dapr runコマンドの処理は、1分ほどで完了します。
次のようなレポートが出力されました。

問題なく、アウトプットされていることを確認できます。
実際には英語ですが、分かりやすくするために、こちらで翻訳しています。
コードの説明
このコードでは、Dapr Agentによるパラレルタスク実行の流れを示しています。
調査質問の生成 (FAN-OUT 前段階)
- まず、
generate_questions()タスクを呼び出して対象トピックに対する調査質問を生成します。
- まず、
並列タスクの実行 (FAN-OUT)
- 生成された各質問に対して、
gather_information()タスクを並列に実行します。各タスクはそれぞれ実行され、全てのタスクが並列に実行される点が特徴です。
- 生成された各質問に対して、
並列タスクの完了待ちと統合 (FAN-IN)
- 並列実行されたタスクの結果を全て受け取った後、
synthesize_results()タスクを呼び出し、全ての調査結果を統合してレポートを生成します。
- 並列実行されたタスクの結果を全て受け取った後、
1つめの質問が完了すると、questionsという変数に、次のような質問リストが格納されます。
{ "questions": [ { "text": "What are the potential environmental impacts associated with the manufacture and disposal of materials used in quantum computing hardware?" }, { "text": "How does the energy consumption of quantum computing operations compare to traditional computing in terms of environmental sustainability?" }, { "text": "What strategies can be implemented to mitigate the ecological footprint of quantum computing technology development and deployment?" } ] }
この場合、3個の質問が、並列タスクとして実行さます。
一応、日本語に機械翻訳したものを以下に示します。
{ "questions": [ { "text": "量子コンピューティングハードウェアに使用される材料の製造および廃棄に関連する潜在的な環境への影響は何ですか?" }, { "text": "環境持続可能性の観点から、量子コンピューティング演算のエネルギー消費は従来のコンピューティングとどのように比較されますか?" }, { "text": "量子コンピューティング技術の開発と展開の生態学的フットプリントを軽減するために、どのような戦略を実施できますか?" } ] }
3つの回答が出揃い次第、最終的な成果物が出力されます。
これを、FAN-OUT / FAN-IN パターンとよびます。
FAN-OUT / FAN-INパターンとは
Fan-Outはタスクを並列実行し効率化、Fan-Inはその結果を集約するプロセスです。分散処理や大規模データ分析に活用されます。
上記は、Dapr Agentに関わられているロベルト・ロドリゲスさんのブログです。
こちらでは、Dapr Agentsのワークフローの説明が行われています。
その中で、前回のシーケンシャル実行と、今回のFan-Out、Fan-Inパラレル実行の説明もされています。

ワークフローのパターンが紹介されていますので興味あれば、ご覧になってみてください。
Daprエージェント並列ワークフロー実行ログ
最後に、実行結果のログを紹介しておきます。
Daprのログが大量に出力されますので、その中から主要な部分だけを抜粋しています。
起動プロセス
ℹ️ Starting Dapr with id dapr-agent-research. HTTP Port: 35455. gRPC Port: 41191 ℹ️ Checking if Dapr sidecar is listening on HTTP port 35455
Daprランタイムの初期化
INFO[0000] Starting Dapr Runtime -- version 1.15.3 -- commit c3687714f9592def48b14b8300bf5170fe8a1bff
INFO[0000] Log level set to: info
WARN[0000] mTLS is disabled. Skipping certificate request and tls validation
INFO[0000] Enabled features: SchedulerReminders
INFO[0000] metric spec: {"enabled":true}
コンポーネント初期化
INFO[0000] Component loaded: workflowstatestore (state.redis/v1) INFO[0000] All outstanding components processed INFO[0000] Loading endpoints... INFO[0000] All outstanding http endpoints processed
サーバー起動
INFO[0000] gRPC server listening on TCP address: :41191 INFO[0000] HTTP server listening on TCP address: :35455 INFO[0000] Dapr initialized. Status: Running. Init Elapsed 23ms
アプリケーション実行
ワークフロー初期化
== APP == INFO:dapr_agents.llm.openai.client.base:Initializing Azure OpenAI client... == APP == INFO:dapr_agents.llm.openai.client.azure:Using API key for authentication. == APP == INFO:dapr_agents.workflow.base:Initialized WorkflowApp with Dapr gRPC host '127.0.0.1' and port '41191'. == APP == INFO:dapr_agents.workflow.base:Discovered workflows: ['research_workflow']
タスク登録
== APP == INFO:dapr_agents.workflow.base:Discovered tasks: ['gather_information', 'generate_questions', 'synthesize_results'] == APP == INFO:WorkflowRuntime:Registering activity 'gather_information' with runtime == APP == INFO:WorkflowRuntime:Registering activity 'generate_questions' with runtime == APP == INFO:WorkflowRuntime:Registering activity 'synthesize_results' with runtime
ワークフロー実行開始
== APP == INFO:root:Starting research workflow on: The environmental impact of quantum computing == APP == INFO:dapr_agents.workflow.base:Starting workflow runtime. == APP == INFO:dapr_agents.workflow.base:Started workflow with instance ID 256979c8f29a4fc29bca479095d2c863.
LLM呼び出し
== APP == INFO:dapr_agents.workflow.task:Invoking Task with LLM... == APP == INFO:dapr_agents.llm.utils.request:Structured Mode Activated! Mode=json. == APP == INFO:dapr_agents.llm.openai.chat:Invoking ChatCompletion API. == APP == INFO:httpx:HTTP Request: POST https://ai-dapr-agent-sample.cognitiveservices.azure.com/openai/deployments/gpt-4o/chat/completions?api-version=2025-01-01-preview "HTTP/1.1 200 OK" == APP == INFO:dapr_agents.llm.openai.chat:Chat completion retrieved successfully.
並列タスク実行
== APP == INFO:dapr_agents.workflow.task:Invoking Task with LLM... == APP == INFO:dapr_agents.llm.openai.chat:Invoking ChatCompletion API. == APP == INFO:dapr_agents.workflow.task:Invoking Task with LLM... == APP == INFO:dapr_agents.llm.openai.chat:Invoking ChatCompletion API. == APP == INFO:dapr_agents.workflow.task:Invoking Task with LLM... == APP == INFO:dapr_agents.llm.openai.chat:Invoking ChatCompletion API.
ワークフロー完了
== APP == INFO:dapr_agents.workflow.base:Workflow 256979c8f29a4fc29bca479095d2c863 completed with status: WorkflowStatus.COMPLETED. == APP == INFO:dapr_agents.workflow.base:Workflow '256979c8f29a4fc29bca479095d2c863' completed successfully! == APP == INFO:dapr_agents.workflow.base:Finished workflow with Instance ID: 256979c8f29a4fc29bca479095d2c863. == APP == INFO:dapr_agents.workflow.base:Stopping workflow runtime.
以上、この記事では、「Dapr Agents」を使って、AIエージェントを並列実行する方法を紹介しました。
並列実行という難しい処理を簡単に実行できることで、今後の応用範囲を広げる手段となる可能性を感じました。
ログで状況は確認できるものの、少しわかりにくいので、次回はDapr Agentのログの可視化についてご紹介します。
Azure AI Agentでのマルチエージェント実装
なお、Azure AI Agentでのマルチエージェントについては、こちらが参考になります。